Part 1: The Data
Tomorrow (March 11th) marks the 3rd anniversary of the Japan Disasters from 2011. As part of my ongoing research on this catastrophe, I have wanted, for the longest time, to document the conversations that transpired on that day, March 11th, entirely as seen on Twitter.
But how would anybody go about retrieving every conversation that transpired on twitter on March 11th? While UCLA’s social media research team was able to collect and archive a quarter of a million tweets (based on relevant hashtags) at the time, this is but a small portion of the whole. But thanks to a collaboration with Takako Hashimoto, whom I met at the Global Humanitarian Technology conference back in 2012, she has provided me with a more comprehensive twitter archive that consists of over 200 million tweets over a 30 day period.
This twitter data archive was provided to me in the form of 30 separate zip files. Each file expands to reveal a single .csv file that balloons to about 8GB each. These csv files were converted to sqlite format (.db) so that we can examine their contents using the command line. Within each .db file is included a row per tweet record, inclusive of the following columns:
id INTEGER PRIMARY KEY, in_reply_to TEXT, body TEXT, nickname TEXT, metadata TEXT, source_url TEXT, retweeted_url TEXT, retweeted_id TEXT, url TEXT, twitter_id TEXT, date TEXT, geo TEXT, lang TEXT, img_url TEXT, author_id TEXT, rel_flag INTEGER
This is what a sample record looks like:
id = 87
in_reply_to =
body = ガスが止まってしまった方へ。東京ガスは震度4で自動停止機能が働く。復帰は簡単。メーターの左上にある黒いキャップを外して中のボタンを奥まで押しこむ。メーター上部の赤ランプが3分点滅するので、その後復活。
nickname = ねね@まつど
metadata = {'urls':[],'hashtags':[],'user_mentions':[]}
source_url = web
retweeted_url =
retweeted_id =
url = http://twitter.com/ym5_t/statuses/46165712405925888
twitter_id = 46165712405925888
date = 2011-03-11 20:08:58
geo =
lang = ja
img_url = http://a0.twimg.com/profile_images/1271955404/img58235088_normal.gif
author_id =
rel_flag = 0
For any single day, there are over 10 millions tweets, making it an almost impossible task to manually sift through the information in any strategic fashion.
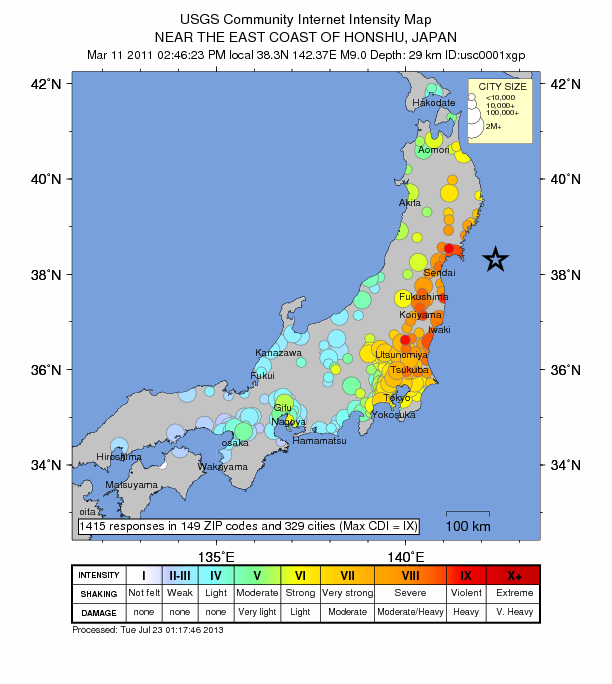
March 11, 2:46:23PM

According to the US Geological Survey, the earthquake struck off the coast of eastern Japan at 2:46:23pm. Yes, that is 2:46pm and 23 seconds. As Japan has perhaps the world’s most advanced earthquake early warning system (source), it took about 20 seconds before these machine operated messages appeared on every public TV channel. It was at 2:46:45pm that these warning tickers appeared on TV (source). Not surprisingly, the first official tweet about the earthquake is also detected at almost same time, at 2:46:50pm:
id = 8625504
in_reply_to =
body = 【緊急地震速報】 第1報 2011/3/11 14:46:19地震発生 最大震度1 震源: 宮城県沖 10km M4.3 震央: 38.2N,142.7E #earthquake
nickname = 緊急地震速報×☆☆☆
metadata = {'urls':[],'hashtags':[{'text':'earthquake','indices':[78,89]}],'user_mentions':[]}
source_url = <a href='http://twitter.com/haruka_eew' rel='nofollow'>緊急地震速報×☆☆☆</a>
retweeted_url =
retweeted_id =
url = http://twitter.com/haruka_eew/statuses/46084644826910720
twitter_id = 46084644826910720
date = 2011-03-11 14:46:50
geo =
lang = ja
img_url = http://a2.twimg.com/profile_images/559842940/komomo_normal.jpg
author_id =
rel_flag = 0
When then, does the first human tweet out in reference to the earthquake? Human vs Machine, which is faster? The analysis to find the answer to this question will be coming shortly in Part II of this series…